
Creating an ECG Data Stream with OpenBCI (Software Programming, Brain Computer Interface)
This article published in the Towards Data Science Magazine, tutors a method to create a live ECG data streaming service for plotting and visualization in Python using Open Brain Computer Interface device (OpenBCI) - Cyton Board.
Technologies used: Python, Bluetooth-Low Energy Protocol, GATT Service Protocol, BrainFlow API
Creating an ECG Data Stream with Polar device (Software Programming, Brain Computer Interface)
This article published in the Towards Data Science Magazine, tutors a method to create a live Accelerometer data streaming service for plotting ECG data with Python using Polar Device.
Technologies used: Python, Bluetooth-Low Energy Protocol, GATT Service Protocol, BrainFlow API

Creating an Accelerometer Data Stream With Polar Device (Software Programming, Brain Computer Interface)
This article published in the Start-up Magazine, tutors a method to create a live Accelerometer data streaming service for plotting ECG data with Python using Polar Fitness Tracker.
Technologies used: Python, Bluetooth-Low Energy Protocol, GATT Service Protocol, BrainFlow API
Getting the beat right!! (Machine Learning, Signal Processing)
This article published in the Towards Data Science Magazine, tutors a method to process the ECG signal with band-pass filters from a Open Brain Computer Interface Device (OpenBCI) - Cyton Board.
Technologies used: Python, Scipy, Band-pass Filter, Notch Filter

Building a Unigram Classifier for Sentiment Analysis (Natural Language Processing, Language Modelling)
Creating a custom Sentiment Classifier using Unigram Language Model for prediction affects of users with functions for custom Tokenization and POS-tagging. I have compared the performance between Gaussian Naive--Bays and Logistic Regression, along with use of Sentiment Lexicoln called Dictionary of Affect and WordNet.
Technologies used: Python, NLTK Corpora, Penn Treebank, Scikit-learn and Numpy
Bigram Maximum Entropy Markov model (MEMM) to do Part of Speech Tagging (Natural Language Processing, POS Tagging)
Creating a custom model for Part of Speech tagging (POS tags) using Universal dependency tagset and training MEMM model on Brown Corpus with a Skip-Bigram Language Model. I have also implemented Viterbi Decoding Algorithm to get the highest-probability sequence of tags for each test sentence.
Technologies used: Python, NLTK Corpora, Brown Corpus, Scikit-learn and Numpy
Extracting the hyper/hyponym relation using Hearst patterns (Natural Langauge Processing, Summarization)
Creating a model for capturing hyper/hyponym relations among noun phrases using training dataset as Wikipedia sentences Corpus and test dataset as BLESS Corpus with NP Chunking and Hearst Pattern implementation algorithms.
Technologies used: Python, Wikipedia Sentences Corpora, Scikit-learn and Numpy

K-Means as an Image Compression Technique (Machine Learning, Image Processing)
K-means clustering algorithm has innumerable real world applications and one of them is image compression. We display the images after data compression using k-means clustering for different values of K (2,5,10,15,20). And also compare the trade-off between image quality and degree of compression.
Technologies used: Python, Numy, Scipy, Matplotlib

Histogram Equilization and Linear Scaling (Computer Vision)
In this project, we performed LAB, LUV and XYZ histrogram equilization along with linear scaling on a number of sample iamges and produced a write-up on the same.
Technologies used: Python, OpenCV, Numpy, and Scipy

Warp Perspective (Computer Vision/Graphics)
We have used OpenCV warp-Perspective and Inter - Linear and tranformative matrix for warping the image on or or more than one plane to produce a new perspective image. All the calculations have neen performed and coded into the project.
Technologies used: Python, OpenCV, WarpPerspective
Modified MNIST with Tensorflow (Computer Vision, Deep Learning)
We reduced the 28 by 28 pixel image to further 7 by 7 pixel image with the help of maxpooling and produced an accuracy of close to 90 % even after a significant Information loss.
Technologies used: Python, Tensorflow, Numpy
Data Imputation technique using K-NN, MICE and Neural Nets (Deep Learning)
Data Imputation is a tecnique to replace with teh missing or erroneous values in the data with an informed guess. We have used 100 distinct senosr data files recorded with the help of Inertial Measurment Unit (IMU) to record upper limbic actvitiy in stroke patients in rhabilitation. Further using data imputation techniques such as MICE, Logistic Regression and Deep Learning we evaluate each of the techniques.
Technologies used: Python, Tensorflow, Datawig, Scikit-learn, Google Colab and MICE
Creating an ML model to predict guest network experience using a Conv Network (Deep Learning)
Our task is to predict the guest network experience with the help of Internet Service Provider network data of each user. The dataset has network sampleset with 40,000 rows and 18 columns.
Technologies used: Python, Tensorflow-GPU, Tensorboard, Google Colab
Spam E-mail Classification Using Naïve-Bays and Logistic Regression (Machine Learning)
We have implemented Naïve-Bays and Logistic Regression for text classification for Spam/Non-SPAM email category. All the calculations for the algorithm were developed using lo-scale keeping in mind underflow and logistic regression with L2 regulrization was implemented as well.
Technologies used: Python, Scikit-learn, Numpy
Implementation of Decision Tree (Machine Learning Algorithms)
I have implemented and tested a decision tree algorithm in Python. Each dataset is divided into Training set, validation set and test set. The implementation has two heuristics for selecting next attribute: Information gain and Variance Impurity.
Technologies used: Python, Pandas, Numpy, Queue
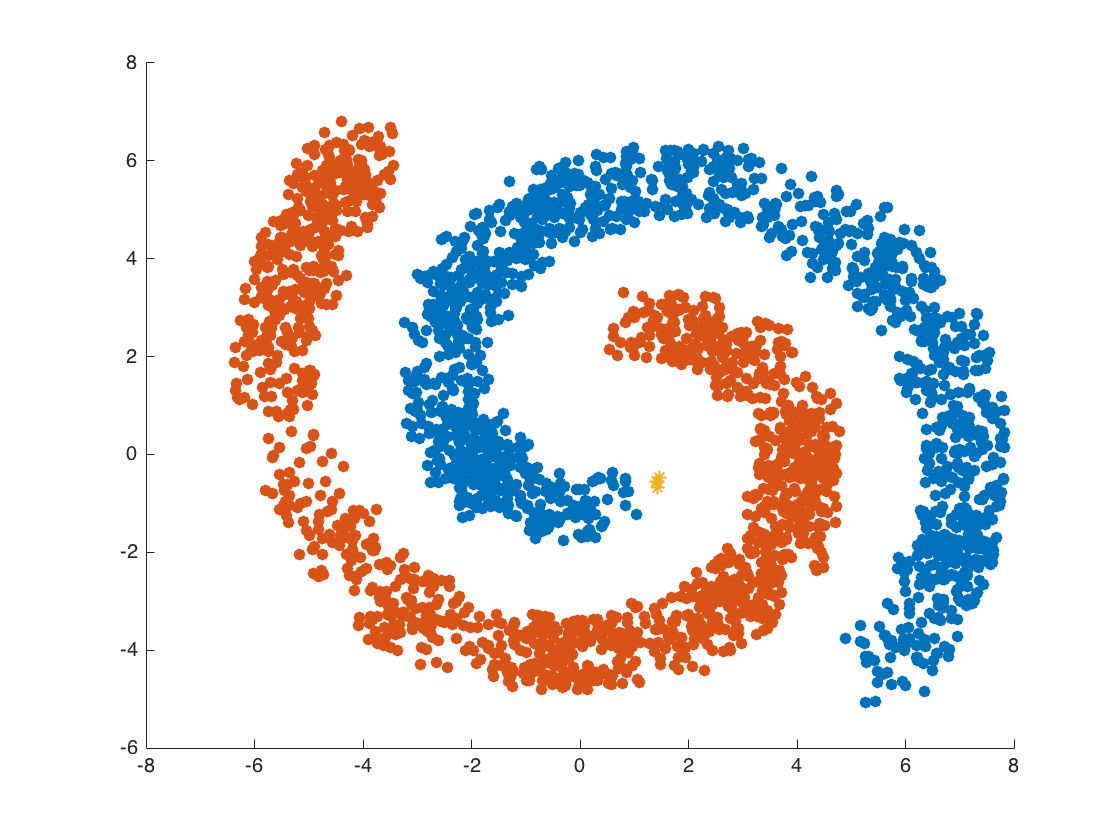
DBSCAN Clustering Algorithm (Machine Learning Algorithms)
Implemented DBSCAN algorithm
Technologies used: Python, Pandas, Numpy, Queue
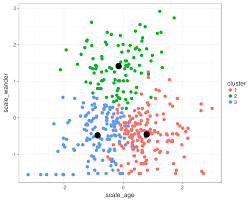
K-Means Clustering Visualizer (Machine Learning Algorithms)
Implemented K-Means clustering algorithm with visualization
Technologies used: Python, Pandas, Numpy, Queue
Hierarchy Clustering Visualizer (Machine Learning Algorithms)
Implemented Hierarchy Clustering algorithm
Technologies used: Python, Pandas, Numpy, Queue